Spark 的特點之一就是 Unified,代表我們只有準備好 Spark cluster 的話,可以直接把 第一個 Spark Application 程式 run 在 cluster 上面,弄一套 Spark cluster 的選項有很多種,有錢的話直接找個雲服務商用他們的服務建立一個就搞定了,像是 AWS 的 EMR 或是 GCS 的 Dataproc,沒錢的話我們只能在 local 端以容器化的方式模擬 Spark cluster 出來了。
容器工具我們使用 Docker,把 Spark 用的 image 準備好後,就可以用 docker compose 一次啟動多台容器來建立我們 local 端的 Spark cluster,讓我們開始吧!
找找巨人的肩膀
找找巨人的肩膀
準備 Spark 環境是最麻煩的地方!感謝 mvillarrealb 寫的 docker-spark-cluster GitHub 庫 ,按造他的步驟可以快速的建立成功 Spark Cluster(standalone 模式),但因為我們想執行的版本為 Spark 3.5.6 和 Python 3.12,Java 版本為 17,而 openjdk image openjdk:17-jdk-slim 的 apt install python3 只能安裝到 Python 3.9, 所以我只能基於 docker-spark-cluster GitHub 庫的內容升級 Python 和 Spark 版本,升級過後的相關配置請參考我的 GitHub 庫 docker-spark-cluster。
clone git 然後 cd 到 cluster/standalone 底下
git clone https://github.com/tshine73/docker-spark-cluster.git
cd docker-spark-cluster/cluster/standaloneDocker Image 準備
基於方便,我順便把 第一個 Spark Application 程式中需要用到的 python library 直接在 dockerfile 中用 pip install 的方式裝好,Dockerfile 內容如下,
FROM openjdk:17-jdk-slim AS builder
ENV PYTHONHASHSEED=1 \
PYTHON_VERSION=3.12.8
RUN apt update -y && apt upgrade -y && apt install -y curl vim wget ssh net-tools ca-certificates build-essential gdb lcov pkg-config libbz2-dev libffi-dev libgdbm-dev libgdbm-compat-dev liblzma-dev libncurses5-dev libreadline6-dev libsqlite3-dev libssl-dev lzma lzma-dev tk-dev uuid-dev zlib1g-dev libmpdec-dev
RUN cd /opt && \
wget "https://www.python.org/ftp/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz" && \
tar -xzvf "Python-${PYTHON_VERSION}.tgz" && \
cd Python-${PYTHON_VERSION} && \
./configure --enable-optimizations && \
make -j `nproc` && \
ln -s /opt/Python-${PYTHON_VERSION}/python /usr/local/bin/python && \
ln -s /opt/Python-${PYTHON_VERSION}/python /usr/local/bin/python3 && \
ln -s /opt/Python-${PYTHON_VERSION}/python /usr/local/bin/python3.12 && \
rm ../Python-${PYTHON_VERSION}.tgz && \
python -m ensurepip --upgrade && \
pip3 install --upgrade setuptools && \
pip3 install matplotlib==3.10.0 pandas==2.2.3
FROM builder AS download_builder
ENV SPARK_VERSION=3.5.6 \
HADOOP_MAJOR_VERSION=3
RUN wget --no-verbose -O apache-spark.tgz "https://dlcdn.apache.org/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_MAJOR_VERSION}.tgz" \
&& mkdir -p /opt/spark \
&& tar -xf apache-spark.tgz -C /opt/spark --strip-components=1 \
&& rm apache-spark.tgz
FROM download_builder AS apache-spark
ENV SPARK_HOME=/opt/spark \
SPARK_MASTER_PORT=7077 \
SPARK_MASTER_WEBUI_PORT=8080 \
SPARK_LOG_DIR=/opt/spark/logs \
SPARK_MASTER_LOG=/opt/spark/logs/spark-master.out \
SPARK_WORKER_LOG=/opt/spark/logs/spark-worker.out \
SPARK_WORKER_WEBUI_PORT=8080 \
SPARK_WORKER_PORT=7000 \
SPARK_MASTER="spark://spark-master:7077" \
SPARK_WORKLOAD="master" \
SPARK_WORKER_DIR="/opt/workspace"
ENV PATH=$SPARK_HOME/bin:$PATH
EXPOSE 8080 7077 7000
RUN mkdir -p $SPARK_LOG_DIR && \
touch $SPARK_MASTER_LOG && \
touch $SPARK_WORKER_LOG && \
ln -sf /dev/stdout $SPARK_MASTER_LOG && \
ln -sf /dev/stdout $SPARK_WORKER_LOG
WORKDIR /opt/spark
COPY start-spark.sh /
CMD ["/bin/bash", "/start-spark.sh"]接下來就可以使用以下命令建立 image。
docker build -t spark-cluster-standalone:3.5.6 .若不幸 Spark 下載連結失效導致建立 image 失敗,可直接使用我在 Docker hub 上的 image 來使用。
docker pull shinest/spark-cluster-standalone:3.5.6 docker tag shinest/spark-cluster-standalone:3.5.6 spark-cluster-standalone:3.5.6
使用 docker compose 啟動 Spark cluster
image 準備好了後,我們就可以試著用 docker compose 啟動 cluster,以下 docker-compose.xml 會啟動 1 個 driver 和 2 executor 共 3 台 container 的 cluster,
services:
spark-master:
image: spark-cluster-standalone:3.5.6
ports:
- "9090:8080"
- "7077:7077"
volumes:
- ../../apps/first_spark_application:/opt/workspace/apps
- ../../data:/opt/workspace/data
environment:
- SPARK_LOCAL_IP=spark-master
- SPARK_WORKLOAD=master
spark-worker-a:
image: spark-cluster-standalone:3.5.6
ports:
- "9091:8080"
- "7002:7000"
depends_on:
- spark-master
environment:
- SPARK_MASTER=spark://spark-master:7077
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=1G
- SPARK_DRIVER_MEMORY=1G
- SPARK_EXECUTOR_MEMORY=1G
- SPARK_WORKLOAD=worker
- SPARK_LOCAL_IP=spark-worker-a
volumes:
- ../../apps/first_spark_application:/opt/workspace/apps
- ../../data:/opt/workspace/data
spark-worker-b:
image: spark-cluster-standalone:3.5.6
ports:
- "9092:8080"
- "7003:7000"
depends_on:
- spark-master
environment:
- SPARK_MASTER=spark://spark-master:7077
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=1G
- SPARK_DRIVER_MEMORY=1G
- SPARK_EXECUTOR_MEMORY=1G
- SPARK_WORKLOAD=worker
- SPARK_LOCAL_IP=spark-worker-b
volumes:
- ../../apps/first_spark_application:/opt/workspace/apps
- ../../data:/opt/workspace/data從 docker-compose.yml 中可以看到,我把專案庫 的 app 和 data 資料夾 mount 到 Spark cluster 的工作目錄下 /opt/workspace/,代表我們可以同步的修改程式以及取得輸出結果,
在來就可以用以下命令啟動 Spark cluster,
docker compose up -d啟動完成後,你就可以用 http://localhost:9090/ 連到 Spark cluster 的 driver 上了,在 UI 上我們也可以看到這個 cluster 中有 2 台 worker 節點可以來執行任務。
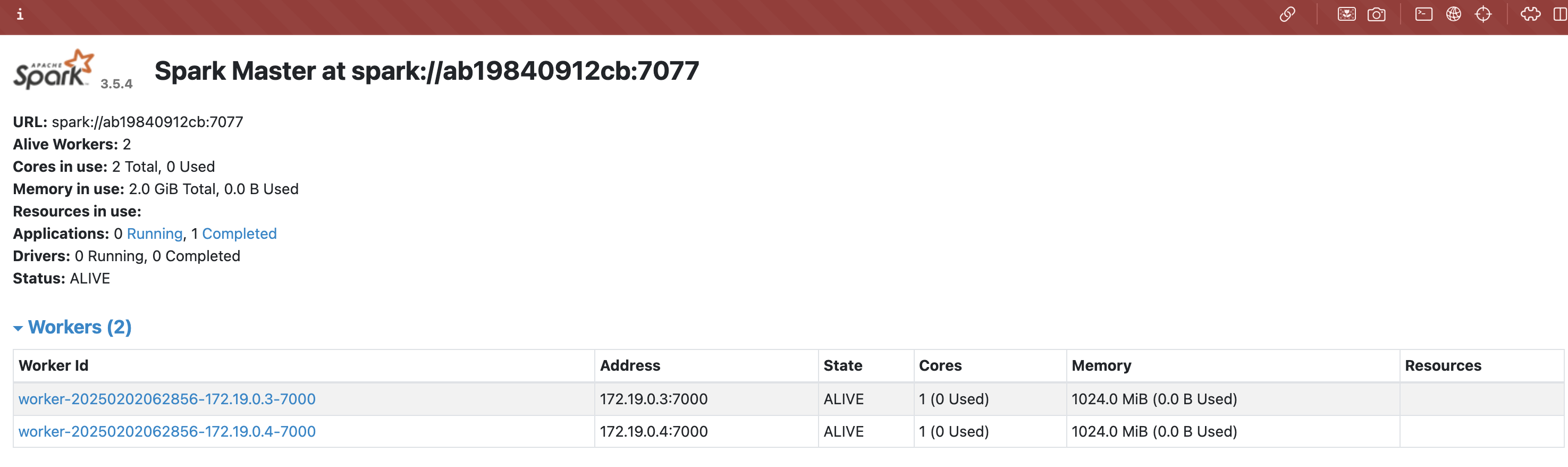
spark submit application
最後,我們就可以把我們在 第一個 Spark Application 寫的程式,submit 在這個 Spark cluster 中執行了,
submit application 前,請先參考 在 第一個 Spark Application 文章,把 movie lens 的資料準備好才行!
命令如下:
docker exec standalone-spark-master-1 spark-submit \
--master spark://spark-master:7077 \
--driver-memory 1G \
--executor-memory 1G \
/opt/workspace/apps/main.pysubmit 後,再進一次Spark UI http://localhost:9090/ 去看,就能看到 Running Application 中有我們剛剛 submit 進去的記錄了,
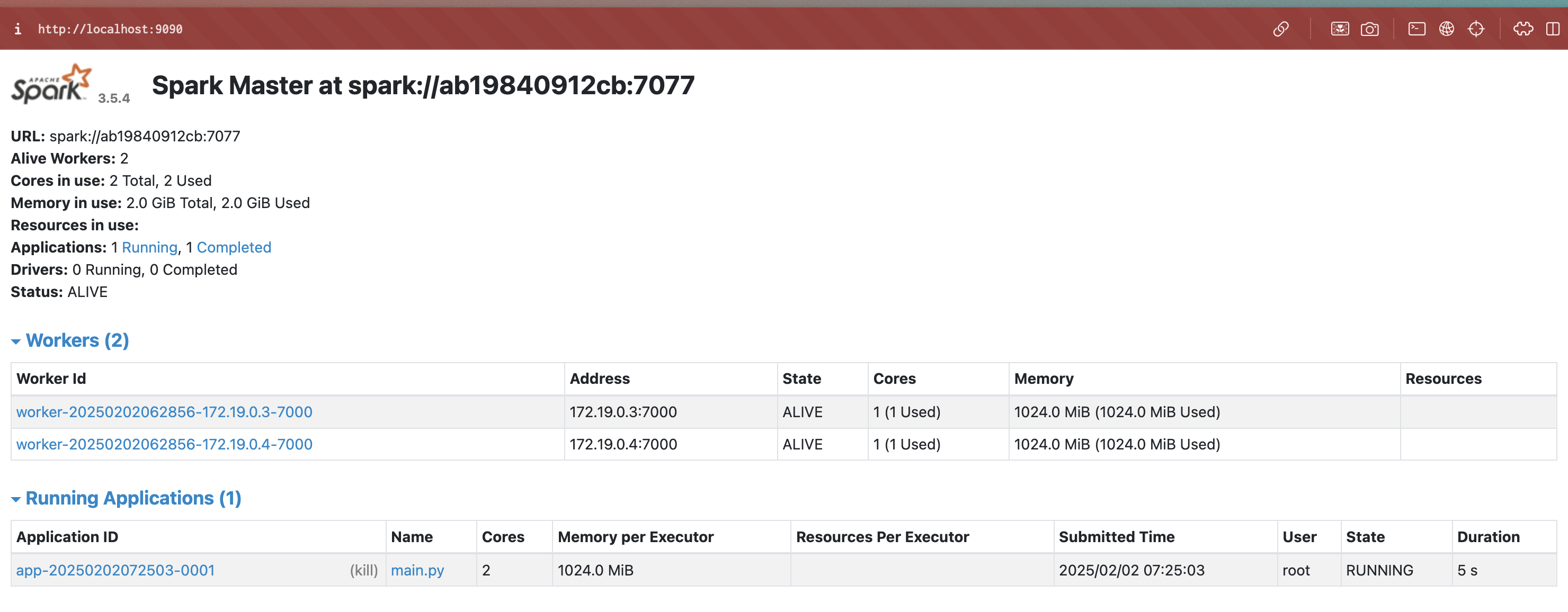
等它跑完,就去檢查一下 data/output 下有沒有結果輸出成功,

有的話,恭喜你已成功將你寫的程式執行在 Spark cluster 中了!
結語
我們基於 mvillarrealb 寫的 docker-spark-cluster github repo,升級 Python 和 Spark 版本到 3.12 和 3.5.6,然後用 docker compose 在 local 端啟動了 1 台 Driver 2 台 worker 的 Spark standalone cluster 來執行我們在 第一個 Spark Application 寫的程式。
其實還有挺多可以優化的,像是 Java 版本我們可以用 15,還有就是打包小一點的 Python 3.12 出來,現在這個 image 打包出來的 Python 太大了,34 M 的樣子,導致整個 docker image size 到 2G 😅 。
但之後若要把 Hadoop 也放進去 image 的話,這個 image size 應該會更大🤣。
